Exercice 1
DM1 - Fourni par Mathys MACIA
Un sondage est réalisé auprès de 40 personnes pour connaître le nombre de livres qu’elles lisent par mois. Les résultats sont les suivants : Par convention, je décide de poser qui représente l’effectif total de la série.
-
Déterminer la variable d’intérêt et son type. La variable d’intérêt est quantitative car elle représente une quantité, et on parle de variable quantitative discrète.
-
Construire le tableau des fréquences associées.
| nombre de livre | 0 | 1 | 2 | 3 | 4 | 5 | TOTAL |
|---|---|---|---|---|---|---|---|
| effectif | 7 | 10 | 8 | 7 | 5 | 3 | 40 |
| fréquences | 0.175 | 0.25 | 0.2 | 0.175 | 0.125 | 0.075 | 1 |
Rappel Soit une variable avec les données et l’effectif total de cette série (le nombre de données). Alors la fréquence notée de est donnée par : Où représente l’effectif de .
Par exemple pour la fréquence des personnes qui ne lisent pas de livre notée où et , on a alors :
On fait de même avec chaque autre effectif correspondant à chacune des possibilités.
- Représenter graphiquement cette série. Puisque nous avons une variable de type quantitative alors nous allons la représenter à l’aide d’un diagramme bâton (diagramme barre). On souhaite représenter graphiquement cette série.
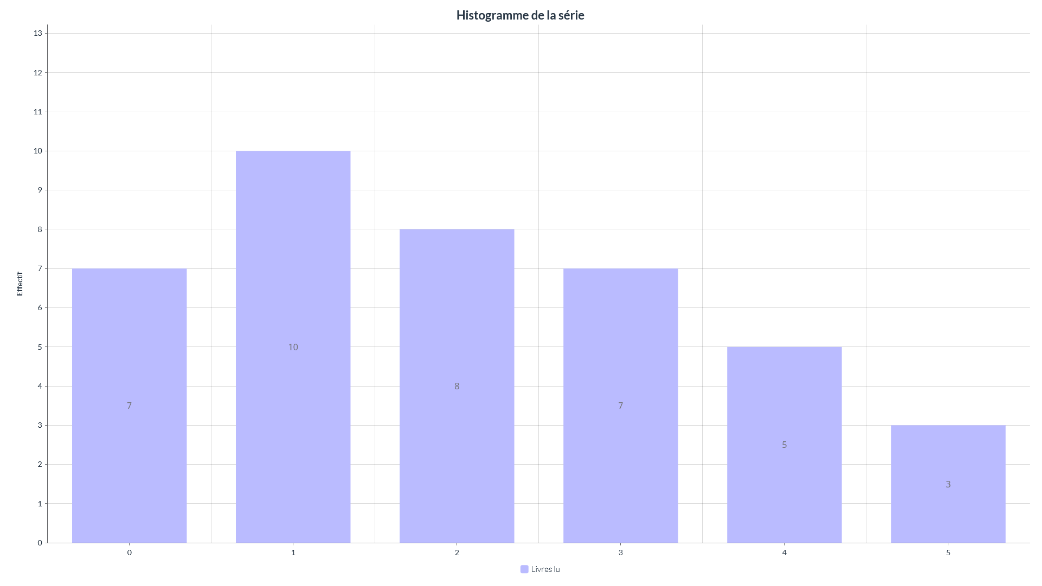
- Calculer le nombre moyen de livre par mois. On chercher à calculer la moyenne de l’effectif.
==Rappel== Soit une variable avec les données et l’effectif total de cette série (le nombre de données). On note la moyenne de la série définie par :
Point méthode Calculer la moyenne d’une série, un échantillon.
- On calcul la somme de toutes les données.
- On divise par le nombre de données
Ainsi, on a : d’où :
La moyenne de livre lu par mois sur cette échantillon est de livres.
- Déterminer la médiane et l’étendue de cette série. Calculons la médiane et l’étendue de cette série.
==Rappels==
- Soit une variable aléatoire avec les données de l’échantilles (de la série). Alors l’étendue de la série notée est définie par :
- Soit une variable aléatoire avec les données de l’échantilles (de la série). Alors la médiane de la série est définie par : >
Ainsi, dans notre série on a :
- d’où L’étendue de la série est donnée par . Dans le même temps, on rappel que . Ainsi : La médiane de cette série est donnée par .
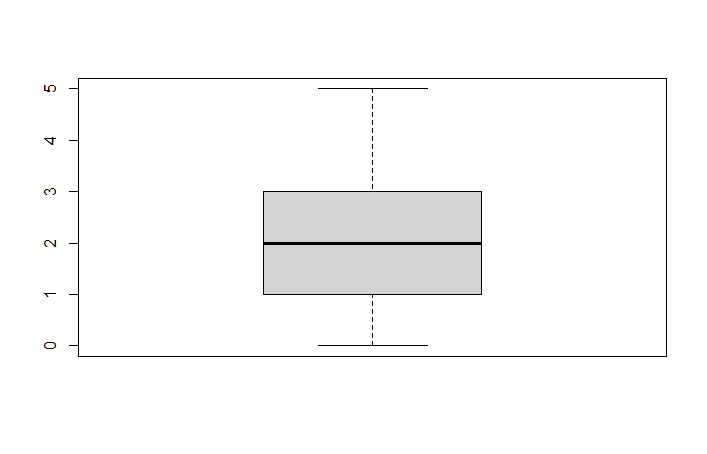
- Tracer la boîte à moustache de cette série.
Point méthode Tracer une boîte à moustache
- Déterminer les quartiles , et . En sachant que :
- Déterminer l’écart interquartile noté et défini par
- Déterminer les bornes de votre boîte à moustache. J’ai décider de noter ces bornes et .
- Tracer votre boîte à moustache en respectant les bornes.
- Tracer la position de la médiane à l’intérieur de votre boîte à moustache.
- Placer (s’il y en a) les outliers (données hors de la boîte).
Ainsi, on a :
- d’où
- Ainsi, je peux calculer les bornes de ma boîte à moustache.
- (on prendra à partir de )
- (on prendra la valeur max de notre série qui est )
On a alors toutes les informations pour tracer notre boîte à moustache.
Tracé effectué avec le langage R
Exercice 2
DM1 - Fourni par Mathys Macia
On s’intéresse au relations entre la fréquence cardiaque au repos () et la pression artérielle moyenne de patients. On a :
Par convention, je note l’effectif total des séries de données.
- Calculer les moyennes des fréquences cardiaques et des pressions artérielles moyennes . On a :
et
- Calculer la variance et l’écart type des deux variables et .
==Rappel== Soit une variable associées à données alors, la variance notée est donnée par : où représente la moyenne de l’échantillon.
Calculons les variances une par une.
et
==Rappel== Soit une variable associées à données alors, l’écart type notée est donnée par : où représente la moyenne de l’échantillon et la variance. Ainsi, l’écart type représente la racine carré de la variance.
Calculons l’écart type de chaque variable :
- Calculer la covariance entre et .
==Rappel== Soit une variable associées à données alors, la covariance notée est donnée par : où et représentent les moyennes respectives de chaque échantillons et .
Calculons cette covariance en respectant la formule donnée. On sait avec les questions précédentes que :
Point méthode Calculer la covariance de deux échantillons
- Tracer la table des avec les colonnes suivantes
- Remplir les colonnes une à une
- Faire la somme des valeurs de la dernière colonne
- Diviser le tout par
| 120 | 80 | -7.6 | -3.53 | 26.828 |
| 125 | 85 | -2.26 | 1.47 | -3.3222 |
| 140 | 90 | 12.74 | 6.47 | 82.4278 |
| 150 | 100 | 22.74 | 16.47 | 374.5278 |
| 130 | 88 | 2.74 | 4.47 | 12.2478 |
| 128 | 83 | 0.74 | -0.53 | -0.3922 |
| 145 | 95 | 17.74 | 11.47 | 203.4778 |
| 138 | 92 | 10.74 | 8.47 | 90.9678 |
| 132 | 87 | 4.74 | 3.47 | 16.4478 |
| 136 | 89 | 8.74 | 5.47 | 47.8078 |
| 142 | 91 | 14.74 | 7.47 | 110.1078 |
| 148 | 98 | 20.74 | 14.47 | 300.1078 |
| 125 | 82 | -2.26 | -1.53 | 3.4578 |
| 140 | 93 | 12.74 | 9.57 | 121.9218 |
| Ainsi, en ajoutant les éléments de la dernière colonne noté , on a : | ||||
| d’où : | ||||
| La covariance est donnée par . |
- Représenter le nuage de point et le barycentre sur le graphique.
==Rappel== Le barycentre représente le point noté de coordonnées .
Le nuage de point ainsi que le barycentre ont été générés avec le langage R.
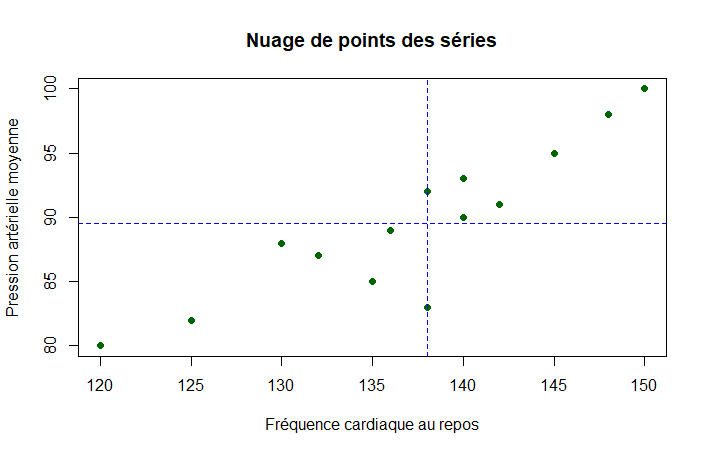 Attention, le nuage de point n’est pas 100% correct, la série contient en fait 14 données et non 15, du coup ça fausse tout, mais comme j’ai la méthode et surtout la flemme de recommencer…
Attention, le nuage de point n’est pas 100% correct, la série contient en fait 14 données et non 15, du coup ça fausse tout, mais comme j’ai la méthode et surtout la flemme de recommencer…
- Proposer un modèle mathématiques pour expliquer la relation entre et . Nous allons utiliser un modèle linéaire de la forme : pour expliquer la relation entre les deux variables. Où :
- représente le coefficient directeur de la droite
- représente l’ordonnée à l’origine
- Utiliser la méthodes des moindres carrés pour estimer les coefficients de la régression linéaire.
Point méthode Utiliser et comprendre la méthode des moindres carrés
- Déterminer l’équation recherchée
- Déterminer les valeurs des coefficients et en sachant que :
où :
- représente la covariance
- l’écart type de
- et les moyennes des séries
- En déduire l’équation de la droite
En suivant à la lettre la méthode donnée juste au dessus, on chercher à déterminer l’équation de la droite . On vas commencer par déterminer , en plus, on a déjà tout calculé précédemment. Ensuite, intéressons-nous à ,
On ajoute un ”^” car ce sont des valeurs estimées.
-
Écrire l’équation de la droite de régression. Ainsi, d’après les résultats déterminés, on a : Le coefficient directeur est .
-
Calculer et interpréter les coefficients de corrélation et de détermination.
==Rappels== Soit une variable associées à données alors, on définit les coefficients de corrélation et de détermination comme suit :
- Coef. de corrélation
- Coef. de détermination où représente la covariance et l’écart type de .
Ainsi, d’après nos calculs précédents on a : et ainsi,
Exercices du TD2
Exercice 1
Une entreprise emploie 500 personnes qui déjeunent à la cantine à l’un ou à l’autre des deux services avec une probabilité égale de manger au premier ou au second service. Si le gérant veut avoir une probabilité supérieure à de disposer d’assez de couverts, combien devra-t-il en prévoir pour chacun des deux services.
Avant de commencer à répondre aux questions Je récupère les informations importantes de l’exercice :
- effectif total
- Notons le fait de “manger au premier service” et “manger au second service”. Ainsi, puisque les probabilités de manger à l’un ou à l’autre des service doivent être égales. Alors, chaque employé a chance de manger au premier ou au second service. On note alors
- On cherche combien de couverts minimum le gérant doit-il disposer à chaque service pour en avoir assez. On notera ce nombre .
-
On numérote les personnes par ordre alphabétique . On note la variable aléatoire valant si la personne mange au premier service sinon . Quelle est la loi de pour ? Les deux possibilités le la loi peuvent être vu comme un échec ou une victoire, ainsi suit une loi de Bernoulli de paramètre . On note : Et lorsque l’on a récupéré les infos, on a défini la loi qui dit que : Ainsi on a :
-
On suppose que les variables aléatoires sont indépendantes pour . Quelle est la loi exacte de la variable aléatoire L’hypothèse de la question dit que chaque variable sont indépendantes, cela semble raisonnable dans le cas d’une numérotation par ordre alphabétique. On rappel que l’on chercher le nombre minimum de couverts à positionner à chaque services. Ici, dans notre cas, représente le nombre de personnes qui mangent au premier service. On note alors : Si détermine le nombre de personnes qui mangent au premier service, alors le restant mangeront au second service, on note alors : Ainsi on chercher le nombre minimum de couverts à disposer à chaque service, pour être certain de disposer d’assez de couverts à chaque service. C’est à dire : La loi exacte de la variable aléatoire est alors donnée par : La loi de est une loi binomiale ).
-
Calculer et .
==Rappel==
- représente l’espérance.
- représente la variance. Puisque suit une loi binomiale tel que alors on a : où représente la probabilité “d’échec”, autrement dit .
Ainsi, en utilisant le rappel fourni on a : 4. Que représente la variable aléatoire dans le contexte ? Comme évoquée précédemment, la variable aléatoire notée représente en fait le nombre de personnes qui mangent au second service.
- Par quelle loi peut-on approcher la loi de ? Préciser ses paramètres. On utilise une loi normale de paramètres : On peut approcher cette loi à l’aider d’un loi normale centrée et réduite.
==Rappel== Lorsque l’on souhaite centrer et réduire une loi normale, alors pour une variable tel que Pour centrer et réduire, afin de suivre une loi normale de paramètre et , on a :
Que l’on vas noter défini par :
- Déterminer le paramètre . On rappel que l’on cherche : On a :
- Ainsi on obtient alors
Ce qui donne en centrant et réduisant, en fin de compte :
où : En négligeant les erreurs d’approximation on cherche minium tel que :
==Rappel==
Ainsi grâce au rappel effectué on a : Ainsi on a : Par lecture des quantiles de la loi normale, on a . Ainsi on a :
- Interpréter la valeur de dans le contexte. Ainsi, puisque pour que le gérant soit certain d’avoir assez de couverts pour les deux services à 95%, il doit placer au moins 272 couverts à chaque services.
Exercice 2
TO DO…