Algorithmique & Programmation 4
C’est quoi un algorithme ?
Définition
On appelle algorithme une suite finie d’instructions précises et ordonnées qui permettent de résoudre un problème, d’accomplir une tâche. Les algorithme sont une base de la programmation informatique et sont utilisés pour automatiser des processus complexes.
Caractéristiques d’un algorithme
- FINITUDE, il doit se terminer après un nombre fini d’étapes.
- PRÉCISION, chaque étape doit être clairement définie (= sans ambiguïté)
- ÉFFICACITÉ, il doit être optimisé :
- en terme de temps d’exécution
- en terme d’utilisation de ressources
- ENTRÉE, il peut recevoir une ou plusieurs entrées
- SORTIE, il produit au moins un résultat
De manière schématique un algorithme peut être vu comme :
Introduction du cours
Un algorithme correct à 90% n’est pas correct.
Nous nous sommes demandés si il est possible de prouver qu’un algorithme est correct. Kurt Gödel (logicien et mathématicien Autrichien) a démontré qu’aucun système formel suffisamment puissant pour décrire l’arithmétique ne peut prouver sa propre cohérence au sein de ce même système. En France (mais pas que), il existe un courant de recherche qui construit des programmes basés sur des algorithmes pour prouver des algorithmes. Par exemple l’assistant de preuve Coq. Si l’on fait un algorithme “soigné”, alors en théorie, il n’y a pas de problèmes pour que le programme le soit lui aussi. Malgré tout cela n’est pas toujours vrai, par contre avoir des bonnes bases est important pour faire un bon programme.
Définition
Le terme efficacité d'un algorithme c’est se demander si mon programme me donne une réponse dans un temps raisonnable.
Attention
- L’efficacité d’un algorithme et l’efficacité d’un programme ne représente pas la même chose.
- L’efficacité d’un algorithme prend en compte la puissance d’un ordinateur, alors il faut prendre en compte plusieurs systèmes, afin de tester l’algorithme plusieurs fois indépendamment du système choisit.
Définition
On appelle programme informatique un algorithme qui a été codé sur machine à l’aide d’un langage spécifique.
Efficacité d’un algorithme
Si l’on dit l’algorithme s’exécute en ceci n’a pas de sens, comme on l’a expliqué au dessus, l’efficacité dépend de la machine. Ainsi, lorsque l’on étudie l’efficacité d’un algorithme on doit répondre à plusieurs questions :
- Sur quelle machine ?
- Pour quelle(s) entrée(s) On considère que l’efficacité d’un algorithme se mesure grâce aux opérations que l’algorithme fait. Pour déterminer l’efficacité de ce dernier on va en fait calculer le nombre d’opérations effectuées.
Exemple : On considère l’algorithme suivant.
Entree :
T un tableau de N entiers
Sortie :
L'entier minimum du tableau T
Algorithme A
m <- T[1]
pour i allant de 2 à N
faire
Si m > T[i]
alors
m <- T[i]
fin si
fin pour
retourner m
fin A
On va voir que l’efficacité sera mesurée en fonction de N.
Voici ce que fait le programme :
- il associe à
mle premier élément du tableau - Il parcours les le tableau à partir du élément jusqu’au
N-ièmedonc l’algorithme boucleN-1 fois - Il compare deux entiers pour savoir lequel est plus petit
- Si vrai : Affectations
- Si faux : Rien
- Retourne
m
Attention
En algorithmique le premier élément d’un tableau, d’une liste est l’élément d’indice
1!
Étudions différents cas de figure possible
- Si
N=10etTtrié dans l’ordre croissant- affectation (au début de l’algo)
N-1=9tour de boucles donc comparaisons Dans le cas d’un tableauTtrié dans l’ordre croissant, le premier élément est forcément le premier élément du tableau, alors la conditionm>T[i]est toujours fausse ce qui implique que l’on ne réaffecte aucunes valeurs àm, elle garde la même valeur tout le temps de l’algo.- retour
- contrôles
Remarque
L’opération
controlec’est le nombre de fois qu’on vérifie siiinférieur ou égal àN. En gros notre boucle dans l’algo elle vas de2->N, ainsi pendant l’exécution la variableiprend les valeurs suivantes :Vous allez me dire pourquoi et bien parce que on prend
iinférieur ou égal àN, du coup sii=Nle tour de boucle vas se faire. Mais lorsqueiprend la valeurN+1c’est à ce moment là que la bouclepourse stoppe. C’est pour cette raison qu’il y a à chaque foisNcomparaisons.
-
Si
N=10etTtrié dans l’ordre décroissant- affectation (au début de l’algo)
N-1=9tour de boucles, donc comparaisons Puisque le tableauTest trié dans l’ordre décroissant alors le plus petit élément du tableau se trouve forcément en fin de tableau, ainsi à chaque tout on réaffecte la valeur couranteT[i]àm. On compte alors affectations supplémentaires- retour
- contrôles
Ainsi ici on a
10affectations et10contrôles.
-
Si
N=1000etTtrié dans l’ordre croissant- affectation (au début de l’algo)
1000-1=999tout de boucles donc comparaisons Tableau trié dans l’ordre croissant donc premier élément forcément le plus petitmreprésente déjà le minimum dès la première affectation.- contrôles
Si on résume globalement ce que l’on apperçoit
- Comparaisons :
N-1 - Nombre de contrôles :
N - Nombre de retours :
1 - Nombre d’affectations :
Meilleure cas
1(dans l’ordre croissant) Pire casN(dans l’ordre décroissant)
Ainsi, on en conclu que le nombre d’affectation dépend de l’entrée même si l’entier N n’est pas fixé.
Comment avancer dans l’analyse algorithmique ?
Définitions
- On appelle opération élémentaire une action de base généralement exécutée en un temps constant selon la machine. Elles permettent d’évaluer la complexité d’un algorithme.
- Les opérations arithmétiques
- pour déterminer le quotient d’une division euclidienne
- pour déterminer le reste d’une division euclidienne
- Les comparaisons
==,<=,>=,<,>,!=(sur des types élémentaires)- Les opérateurs logiques
- ET OU qui prennent
2 booléens- NON qui prend
1 booléen- Les opérations de contrôles permettent de gérer les boucles, les conditionnelles, le résultat
Dans nos études, nous considérerons que la taille de l’entier est minimale, même si cette dernière dépend du codage.
Remarque
Si on fixe une base et un nombre , alors on aura pour chiffre de :
Pour rappel Soit alors on note sa valeur entière supérieure par .
Exemple : Pour ,
- en base possède deux chiffres
- en base on a ()
- en codage unitaire on a
Remarque
2 logs sont égaux à une constante près.
Exemple : Si on prend entiers codés sur octets on aura alors octets utilisés. Pour entiers on aurait , c’est une fonction linéaire.
Définition
On appelle ordre de grandeur la tendance d’une courbe quand augmente.
En algorithmique, L’ordre de grandeur est utilisée pour évaluer la tendance du temps d’exécution (ou de l’espace mémoire) requis par un algorithme en fonction de la taille donnée. Cela permet en fait de classer les algorithmes selon leur efficacité sans se soucier des constantes ou des termes qui influent peu. L’ordre de grandeur est notée , avec la notation Big-O qui donne une approximation asymptotique de la complexité.
Dans ce cours, on utilisera la notation de Landau créée par Brechmann en 1894 et popularisée par Landau, qui permet de décrire le comportement des fonctions selon la tendance de , pour objectif de déterminer la complexité de certains algorithmes.
Dans l’objectif de mieux comprendre la notation de Landau, nous allons utiliser quelques exemples.
Rappel
Dans le cadre des Maths pour l’info en L1 La notion de suite/fonction dominée a été introduite. Soient et deux fonctions, on dit que est dominée par si et seulement si :
En français, on cherche un rang à partir duquel est plus petit ou égal à .
Exercice
- On considère une fonction et on veut montrer que .
- On considère montrer que .
Correction
Pour plus de facilité nous allons prendre chaque termes de la fonction et étudier leur signe par rapport à .
Ainsi si je regroupe les trois inégalités et que je prend le rang qui permet de respecter les conditions, j’obtient :
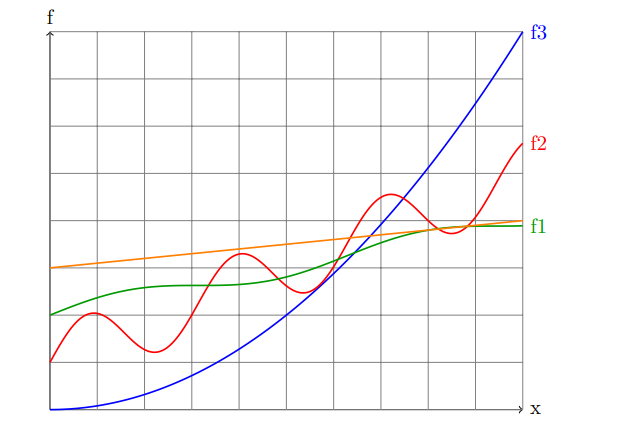 En reprenant les fonctions données par M.Sanlaville pendant les CMs, étudions asymptotiquement les allures des courbes , et .
En reprenant les fonctions données par M.Sanlaville pendant les CMs, étudions asymptotiquement les allures des courbes , et .
- Pour La courbe verte semble croire lentement avec peu d’oscillation, son comportement est semblable à ou
- Pour La courbe rouge semble croire plus vite que mais présente plus d’oscillations. En la lissant on peut définir qu’elle suit une tendance semblable à .
- Pour La courbe bleue semble croitre plus rapidement que les deux autres, de manière exponentielle ou quadratique. On a par exemple.
Propriétés
- Soit une fonction alors on a Une fonction se domine elle même.
- Soit et deux fonctions :
En gros, si ça revient à dire que et croient de manière proportionnelle, qu’elles ont la même complexité asymptotiques.
Complexité des algorithmes
Définitions
- On appelle complexité au pire d’un algorithme la fonction qui permet de donner le nombre maximum d’opérations élémentaire qu’effectue un algorithme en fonction de la taille de l’entrée. Généralement on ne donne pas une fonction exacte mais plutôt un ordre de grandeur
- À l’inverse, on appelle complexité au mieux d’un algorithme la fonction qui permet de donner le nombre minimum d’opérations élémentaire que fais cet algorithme en fonction de .
- La complexité en moyenne est plus hypothétique, on connais la probabilité des entrées, on cherche la fonction qui donne le nombre moyen d’opérations élémentaire.
Pour la complexité d’une boucle pour à itérations et (constant) opérations élémentaire
On va avoir une complexité en mais, puisque est une constante, on peut la négliger et on se retrouve dans le pire, le meilleure des cas et en moyenne à .
Exemple : On considère les boucles suivantes :
pour i = 1 -> N-1
pour j = 0 -> N-i
Comparer T[j], T[j+1]
peut être changer j, j+1
Dans notre cas :
- On dispose de deux boucles, une sur
iet une surj. - On a deux opérations élémentaires constantes Comparer échanger
En regardant les boucles de plus près :
- Boucle externe
De
iallant de1àN-1on boucle doncN-1fois dans tous les cas - Boucle interne
De
iallant de0àn-iPuisqueidémarre à0, alors on ajoute obligatoirement un tour de boucle supplémentaires quelque soitNAinsi, on boucleraN-i+1fois pour toutes les possibilités deNAinsi, le nombre d’opérations élémentaires de la boucle interne est donnée par :
- constante, le nombre d’
OE - La somme regroupe toutes les comparaisons effectuées pendant l’exécution de l’algorithme
En gros le nombre d’opérations de la boucle interne c’est la somme du nombre d’itérations de cette dernière en fonction de
imultiplié par le nombre d’OE.
Remarque
Dans la suite l’acronyme
OEsignifie opération élémentaire.
Complexité du tri à bulle
Le tri à bulle (ou bubble sort) est un algorithme de tri permettant de trier progressivement les éléments d’un tableau en échangeant les éléments adjacents pour les placer progressivement dans le bonne ordre. Le principe
- Compare les éléments adjacents
- Si deux éléments sont pas dans le bon ordre il sont échangés
- Après chaque passage, l’élément le plus “grand” se retrouve en fin de tableau
Algorithme du tri à bulle
Fonction tri_a_bulle(T)
n ← longueur(tableau)
Pour i allant de 0 à n - 1
Pour j allant de 0 à n - i
Si T[j] > T[j + 1] alors
Échanger T[j] et T[j + 1]
Fin Si
Fin Pour
Fin Pour
Fin Fonction
Ainsi, la complexité du tri à bulle est la suivante :
On décompose les sommes pour que ce soit plus simple :
Ainsi on se retrouve avec :
Propriétés des sommes
Propriétés sur les sommes
à retenir sur les sommes, connu depuis algèbre de base… en ajoutant les aspects drôles de l’algorithmique et des complexités
Propriétés sur les sommes
Propriétés sur les sommes
Propriété sur les sommes
Exemple : On considère le code suivant :
pour i allant de 1 à N
pour j allant de 1 à N
pour k allant de 1 à N
// Instructions constantes OE
On a alors une complexité définie par :
Pour une boucle TANT QUE
tant que <condition>
faire
// k opérations élémentaires, k = Cste
Rappel
On note
Csteune constante.
Alors, le code suivant possède une complexité au pire. Il faut alors trouver , le nombre d’opérations élémentaires maximum.
Algorithme récursif
Définition
Un algorithme récursif est une méthode permettant de ressourdre des problèmes en s’appelant elle-même, afin de résoudre des sous-problèmes du même type. généralement la récursivité est utilisé pour des problèmes qui veut être divisés en sous-problèmes similaires. Un algorithme récursif nécessite :
- Une condition d’arrêt, en gros c’est le moment ou l’algorithme arrête de s’appeler lui-même (sinon récursion infinie)
- Appel récursif
Pour mieux comprendre la notion de récursivité prenons un exemple concret
Recherche dichotomique
L’algorithme de recherche dichotomique (ou recherche binaire) est un algorithme efficace permettant de rechercher un élément dans un tableau trié. Il repose sur le principe des méthodes “diviser pour régner” en réduisant l’espace de recherche de moitié à chaque étape. Principe de base :
- On choisit un
xrecherché - On se place au milieu du tableau
Ttrié - On récupère
ml’élément au milieu du tableaux=mon arrête de chercher, on a trouvé.x<malors puisque le tableau est trié tous les éléments aprèsmseront plus grands, alors on réeffectue la recherche sur la moitié gauche.x>mOn réeffectue la recherche sur la moitié droite.
- Si les indices se croisent, ou si on a trouvé
x, on s’arrête.
Algorithme de la recherche dichotomique
Entrees :
D la liste d'élément trié
x l'élément cherché
deb l'indice de début de la partie de tableau
fin l'indice de fin de la partie du tableau
Sortie :
indice de l'élément x si trouvé
Algorithme rechDico
SI debut > fin
ALORS
RETOURNER -1
milieu <- (debut + fin) DIV 2
elemMiddle <- D[milieu]
SI elemMiddle = x
ALORS
RETOURNER milieu // Mot trouvé, retourne sa position
SINON SI x < elemMiddle
ALORS
rechDico(D, x, deb, millieu-1) // Chercher dans la moitié gauche
SINON
rechDico(D, x, millieu+1, fin) // Chercher dans la moitié droite
FIN SI
fin algo
Dans cette algorithme,
pour déterminer la complexité on compte le nombre d'OE (hors appels récursifs ) qui déterminera le nombre d’appels.
Ici, la complexité ne sera pas la même selon les cas
-
Dans le meilleur des cas L’élément est pile au milieu du tableau alors on a
-
En moyenne, on ne peut pas déterminer car on a pas d’informations sur la taille des l’entrées ou autre
-
Dans le pire des cas L’élément est sois le tout premier élément soit le tout dernier alors la méthode vas se faire sur des parties de tableau divisées de moitié à chaque appel récursif jusqu’à ce qu’il ne reste qu’un élément à comparer. Autrement dit le nombre d’opérations va être :
Ainsi dans le pire des cas la complexité de la recherche dichotomique est donnée par .
Avec un nombre d’opérations élémentaires qui suit une fonction avec la taille de l’entrée, alors la complexité sera donnée par . Le nombre d’opération peut dépendre aussi de la taille des données traitées par appel.
Exemple : Taille des données par appel récursif : puis puis , … respectivement de taille , , . Et (linéaire).
Alors la complexité au pire, lorsque l’on fait tous les appels de à est donnée par :
On peut aussi avoir le cas où il y a 2 appels un appel sur une taille Ti qui à l’intérieur contient deux appels T{i+1} et T{i+1}'.
Un exemple trop vu : Fibonacci
La suite de Fibonacci est définie par :
Ainsi on obtient l’algorithme récursif suivant :
Entree :
N le rang de la suite
Sortie :
Le terme de rang n de la suite de fibo
Algorithme fibo
SI N=0 OU N=1
ALORS
RETOURNER 1
SINON
RETOURNER fibo(n-1)+fibo(n-2)
FIN SI
FIN Algo
Alors, pour un appel au rang N on peut avoir deux appels qui sont sur N-1 pis N-2.
ARBRE D’APPELS DE LA SUITE DE FIBONACCI
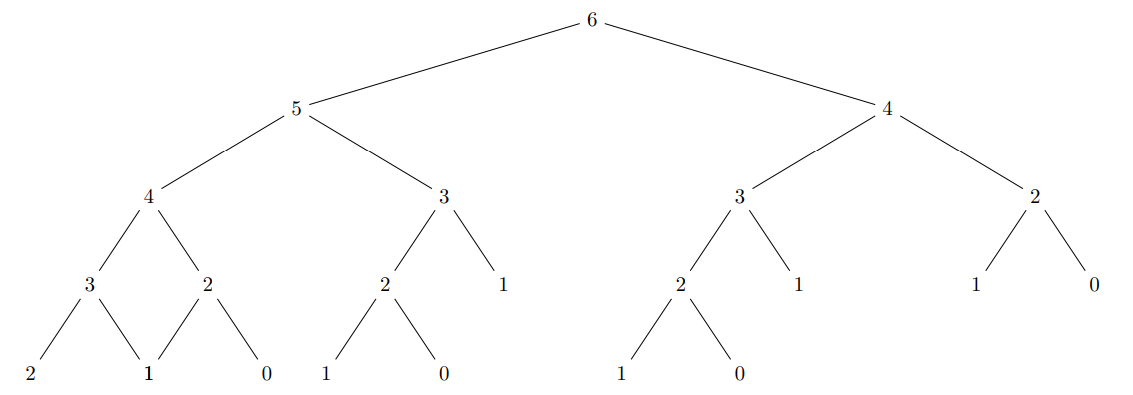 On voit que :
On voit que :
- Pour
N=6on fait 23 appels - Pour
N=5on fait 13 appels - Pour
N=4on fait 8 appels On peut déduire que le nombre d’appels est exponentiel lorsqueNdevient grand.
En général :
Si on coupe l’ensemble des données en parties de taille alors :
où représente le nombre d’OE à l’intérieur de l’appel.
- Au départ :
N=n - À la fin :
N=Csteou condition validée
Attention
Les formules suivantes s’appliquent uniquement aux algorithmes où la relation de récurrence est de la forme :
où :
- représente le nombre de sous-problèmes
- le facteur de réduction de taille
- le coût des opérations
Théorème maître (Master Theorem)
- Si pour
Dans ce cas, la fonction croit plus lentement que , donc le coût total est dominé par le temps de résolution des sous-problèmes.
Alors- Si
Alors
Le coût des sous problèmes sont du même ordre.- Si avec
Alors
Dans ce cas croît plus vite que le coût des sous-problèmes donc domine.Si alors
Alors on dispose de 3 cas différents
- donc
- donc
- donc
Dans le cas de la recherche dichotomique, c’est le second cas. On prend alors et , qui est une constante pour la formule générale. On se retrouve avec le cas : .
Notion de finitude d’un algorithme
La première chose demandée à un algorithme, c’est de terminer son exécution en un temps fini. Ce n’est pas évident pour un algorithme.
Considérons une boucle tant que (boucle for : nbBoucle fixé à l’avance), en supposant que le nombre d’OEdans la boucle est bornée.
Définition
On appelle variant noté pour une boucle une quantité entière, bornée et strictement décroissante à chaque itération de .
Rappel
Le terme borné signifie que le variant est compris dans un intervalle, qu’il existe un nombre plus petit ou égal (minoré) et un nombre plus grand ou égal (majoré).
Pour montrer qu’un algorithme est fini (= terminaison) il faut analyser s’il comporte un nombre fini d’étapes et s’il s’arrête après un temps fini pour toutes les entrées possibles.
Définition
On dit d’un algorithme qu’il est fini s’il se termine après un nombre fini d’étapes, quelque soit l’entrée choisie.
Objectif
- Identifier un variant qui décroit à chaque itération
- Vérifier l’absence de boucle infinies
- S’assurer que chaque “branches” de l’algo mène à une terminaison
Considérons l’algorithme suivant
var D <- LT - LA
TANT QUE D > 0
FAIRE
LA <- LA+D
LT <- LT + D/2
D <- LT-LA
FIN TANT QUE
RETOURNER (LA)
Quelques précisions :
- Les entrées
LA, LTdeux réels, dans notre exemple considérons queLA=0etLT=100
- Sortie
LAun réel Les variablesLAetLDreprésente nt respectivement la longueur d’Achille et la longueur de la tortue etDla distance entre eux. Sauf que puisqueLT>LA, alors la distance ne sera jamais inférieur ou nul alors, Achille ne rattrapera jamais la tortue. Hors, si on programme cet algorithme en JAVA par exemple, il se termine, sinon il est infini en théorie.
Exemple 01 : Prenons en compte l’algorithme de recherche du plus grand diviseur commun par l’algorithme d’Eulcide.
Entree :
x, y deux entiers
Sortie :
x le pgcd(x, y)
Algorithme PGCD
a <- x
b <- y
SI a<b
ALORS
echanger a et b
FIN SI
TANT QUE b > 0
FAIRE
(q, r) <- divEuclidienne(a, b)
a <- b
b <- r
FIN TANT QUE
RETOURNER a
FIN Algo
- À chaque tour de boucle, on a prend la valeur du reste de la division euclidienne de par .
bdiminue strictement à chaque itération carr<bpar définition- Donc
bdiminue strictement à chaque itération best un entier et est borné inférieurement par Dans notre cas, le variant .
Ainsi :
- à chaque itération diminue d’au moins
- comme est initialement un entier fini et qu’il ne peut pas être nul ou plus petit, la boucle se terminera après un certain nombre fini de tour
- Lorsque , la boucle s’arrête et le programme renvoie Ces trois aspects prouvent la finitude de mon algorithme, décroit à chaque itération, a une borne inférieure et une borne supérieur , et prend valeurs initiale dans un ensemble ordonnée, les entiers naturels.
Exemple 02 : Considérons un autre algorithme, celui de la puissance de . Qui permet de déterminer si l’entier passé en paramètre est pair.
Entree :
x l'entier a tester
Sortie :
pair le booleen qui défini si x est pair
Algo puissanceDeux
m <- x
pair <- VRAI
TANT QUE (m>1) et PAIR
FAIRE
pair <- m est pair
m <- m DIV 2
FIN TANT QUE
RETOURNER PAIR
FIN Algo
Ici, cherchons le variant. On remarque vite que :
mest borné inférieurement parmest borné supérieurement parxm DIV 2implique quemdécroit de moitié à chaque itération Ainsi ici, notre variant est donné par . D’où puisque , quemest bornée, diminue à chaque itération, la boucle tant que s’arrêtera après un nombre fini d’opérations, et lorsqu’elle se termine l’algorithme renverrapair. Ainsi nous venons de montrer la finitude de l’algorithmepuissanceDeux.
Notion de correction d’un algorithme
La correction d’un algorithme désigne la propriété selon laquelle un algorithme produit systématiquement le résultat attendu. Autrement dit, un algorithme est dit correct lorsqu’il fournit toujours une solution correcte pour toute les entrées valides.
Définitions
- On dit qu’un algorithme est partiellement correct si il fourni un résultat correct lorsqu’il finit forcément par se terminer (= finitude). Mais, cette notion de garantit pas toujours que l’algorithme se termine.
- On dit qu’un algorithme est totalement correct quand il est à la fois partiellement correct et qu’il termine pour toutes les entrées possibles. Autrement dit un algorithme est correct lorsqu’il se finit et fournit des sorties valides pour toutes entrées valides.
Méthode pour montrer la correction Vérifier la correction d’un algorithme peut se faire de plusieurs façons
- Preuve par induction (utilisé pour des algorithmes récursifs/itératifs)
- Montrer que l’algorithme fonctionne correctement pour un cas de base.
- Supposer qu’il fonctionne pour un cas arbitraire
- Démontrer qu’il fonctionne pour le cas suivant Raisonnement par récurrence
- Invariant de boucle (algorithmes itératifs)
- Identifier une propriété qui est vraie avant, pendant et après chaque itération de la boucle.
Considérons un algorithme avec :
- Entrée :
Un algorithme qui prend en entrée des éléments de l’ensemble . - Sortie :
Une algorithme qui renvoie un résultat qui appartient à un ensemble . - Variable :
Y
Variable interne utilisée par l’algorithme pendant l’exécution. On note : - un prédicat vérifié pour tout .
On parle de PRÉCONDITION. - un prédicat vérifiant si la sortie produit par l’algorithme est correcte pour l’entrée .
On parle de POSTCONDITION.
On dit que l’algorithme est correct si :
- Il se termine (finitude)
- est vraie pour tout couple entrée sortie
Reprenons l’exemple précédant
L’algorithme ici que l’on vas nommer permet de vérifier si un entier x passé en paramètre est une puissance de .
Entree :
x l'entier a tester
Sortie :
pair le booleen qui défini si x est pair
Algo puissanceDeux
m <- x
pair <- VRAI
TANT QUE (m>1) et PAIR
FAIRE
pair <- m est pair
m <- m DIV 2
FIN TANT QUE
RETOURNER PAIR
FIN Algo
Si on récupère les informations à disposition :
- Les entrées possibles sont des (= entiers naturels)
- La sortie est un booléen permettant de dire si
xest une puissance de
Étapes de l’algorithme :
- On associe à la variable
mla valeur dex. pairest initialiser àVRAIcar on suppose quexest une puissance de2.- La boucle TANT QUE boucle lorsque :
m>1(on a pas encore atteint la valeur1)pairest encoreVRAIles divisions précédentes ont permis de maintenir la parité dem.
- Corps de la boucle TANT QUE
parestVRAIsimest pairmest divisé par2
- On retourne la valeur finale de
pair
Analyse de l’algorithme Pourquoi cet algorithme fonctionne t-il ? Par définition un entier est une puissance de si : Il est positif strict Il peut être divisé plusieurs fois par jusqu’à obtenir sans jamais devenir impair lors des divisions successives.
Pour alors on a :
On s’arrête car on a attend , est donc une puissance de . Pour on a :
On s’arrête car est impair, ainsi n’est pas une puissance de .
Preuve de la correction
-
Précondition : L’entier en paramètre doit être strictement positif, on note
-
Postcondition : L’algorithme retourne
VRAIsi et seulement si est une puissance de . On note
Correction partielle
- Initialisation
Au départpair=VRAIetm=x - Invariant de boucle
À chaque itération de la boucleTANT QUE, sipairresteVRAI, alors tous lesmprécédant sont pairs, ce qui est nécessaire pour qu’un nombre soit une puissance de . - Terminaison
La boucleTANT QUEse termine lorsquem=1ou lorsquepairdevientFaux(une division par ) produit un nombre impaire.
On noteV=mle variant car il décroit à chaque tour de boucle d’au moins , alors il y aura forcément un moment ou soitm=1oum<1dans ce cas la boucle s’arrête et l’algorithme renvoi la valeur depair. - Conclusion
Si l’algorithme se termine avecpair=VRAIalorsxsera forcément une puissance de .
Correction totale
- La variable
mest divisée par2à chaque itération, donc elle décroit strictement et atteindra forcément ou une valeur inférieure à , assurant la fin de la boucleTANT QUE.
Cherchons la formule de l’invariant
Définition
On appelle invariant une propriété qui reste vraie tout le long de l’exécution d’une boucle ou d’un programme, à chaque itération.
Reprenons la boucle TANT QUE
TANT QUE (m>1) et PAIR
FAIRE
pair <- m est pair
m <- m DIV 2
FIN TANT QUE
Alors on a :
mla variable divisée par2à chaque itérationkUn compteur représentant le nombre d’itération effectuées.- On note
restela valeur qui représente le reste des divisions précédentes.- Vaut si
mdevient impaire après une division - Sinon
- Vaut si
Ainsi on a :
- avec si c’est une puissance de On obtient alors l’invariant suivant :
Essayons de montrer ce dernier par récurrence.
-
Initialisation au début de l’algorithme On a
m=x,k=0etreste=0Donc :L’invariant déterminé est vrai pour l’initialisation.
-
Récurrence On suppose que est vrai pour itérations, montrons que cela se maintient pour itérations. On a :
Au rang , je sais que , alors lorsque l’on divise pour l’itération suivante, on obtient :
d’où on se retrouve avec :
Ainsi au terme on retrouve le quotient et le reste de la division de l’itération ainsi que le reste de la division précédente. La structure de l’invariant est globalement respectée à chaque itération.
Exemple supplémentaire : On considère l’algorithme qui permet de rechercher le maximum dans une liste de nombre.
Entree :
Tableau T de nombres
Sortie :
Element le plus grand du tableau T
Algorithme maximum
max <- T[1]
POUR i = 2 à N
ALORS
SI T[i]>max
max <- T[I]
FIN SI
FIN POUR
RETOURNER max
FIN maximum
On peut noter T = [t1, t2, ..., tn] le tableau.
Dans l’objectif de prouver la correction de l’algorithme, il faut trouver un invariant de boucle.
Rappel
Un invariant de boucle représente une propriété qui est vrai avant, pendant (chaque itération) et après (sortie) uen boucle.
Soit un entier strictement positif, on note la propriété “max = maximum([t1, t2, ..., ti])”. En gros, représente la taille de l’entrée, le nombre d’éléments du tableau.
- Initialisation :
Pour , alors le tableauTne contiendra qu’un seul élément. Si on exécute l’algorithme, avant de rentrer dans la boucle, le minimum est le premier élément du tableauT[1], ainsi la propriété est vraie AVANT LA BOUCLE. - Hérédité :
Supposons que soit vraie au début de l’itération ,, c’est à dire quemax = maximum([t1, ..., ti]), montrons que me résultat sera conservé après itération de la boucle. On cherche à montrer que :max = maximum([t1, ..., ti, ti+1]). On a à l’itération ,max = maximum([t1, ..., ti])SI T[i]>max max <- T[I] FIN SI- Si
T[i+1] <= maxalors sa valeur ne change pas selon la conditionIFde l’algorithme - Si
T[i]>maxalors la valeur du maximum prend comme nouvelle valeurT[i]qui est donc la plus grande valeur du tableau
Ainsi, dans les deux cas présentés ici, la valeur du maximum du tableau est conservée, reste vraie à chaque itération.
- Si
- Conclusion :
L’invariant reste vrai après la dernière itération de la boucle, d’indicei. On peut noter alors que le résultat de l’itérationi-1etirestent les mêmes pour un tableau deiéléments :
max = maximum([t1, ..., ti-1]) = max = maximum([t1, ..., ti)
On vient donc grâce à l’invariant de montrer la correction partielle de cette algorithme.
Pour terminer, l’algorithme possède une boucle for qui se termine après un nombre connu d’itérations. Ainsi l’algorithme est fini.
En somme :
- est fini
- respecte bien une propriété avant, après chaque itérations et à la sortie de la boucle.
Remarque
Ainsi pour montrer la correction il faut :
- Prouver que l’algorithme est fini
- En utilisant un variant
- Déterminer un invariant et démontrer par récurrence que ce dernier est vrai avant la boucle, pendant chaque itération, et à la sortie de la boucle.
Compléments
- Correction examen 2024 : Correction de l’examen AP4 2024